Poetry Bot - step by step
A few months ago I had a simple idea: what if someone woke up every day to a love poem, first thing in the morning, to find it in their inbox?
As everyone knows, I intend to speed-run the the ‘GitHub Certified: Agentic AI Developer (beta)’ course on 27 June 2026.
TLDR:
I am told that ‘AI’ (large language models) are useful for mundane and time-consuming tasks. In an attempt to prove this wrong, I wrote a program that sends my fiancée a love email each day in different languages.
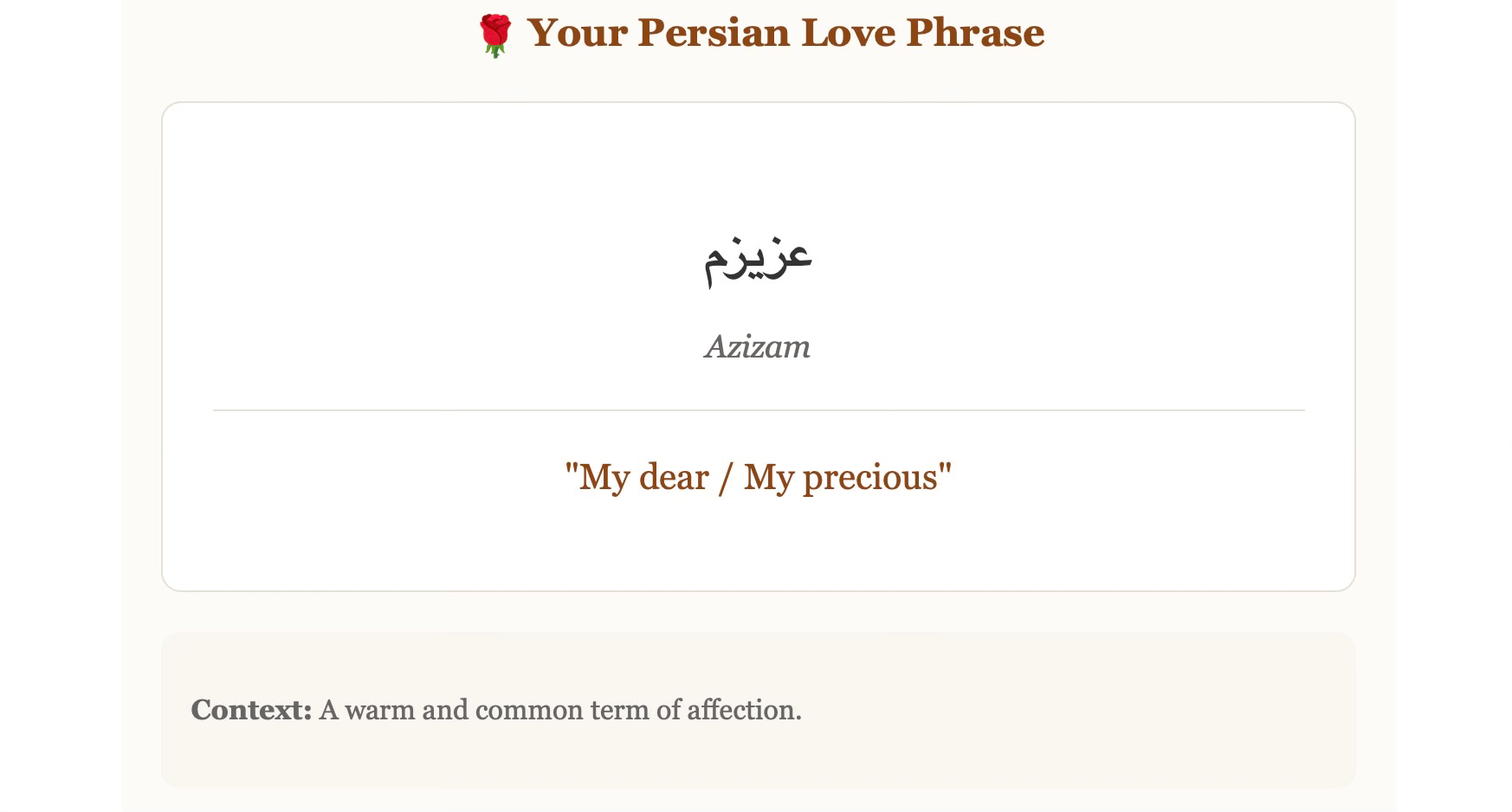
Each day a different love phrase arrives - translated into English from a different language.
This points at a very interesting element of LLMs. If their training data is too small, and incorrect, then that they have trouble translating exactly from one language to another. At the same time, if the training data is too large, but sometimes correct and possesses enough information to make a probabilistic guess at the context, then the model needs to know where the signal is in the noise (Claude Shannon would love this).
This is not a trivial matter - yet this toy makes the underlying principles clear.
How many companies, particularly regulated insurance and financial services firms, also law firms, have an ‘AI Strategy’? One would ask:
What’s the training data?
Are the data reliable?
Are they sufficiently complete for the context?
How does one increase fidelity? (in the information theory sense [signal/noise])
And how can we add even more complexity before another repo is needed - but also must be linked?
Stay tuned because - someday (i.e.) these kinds of things find themselves in Courts.
There are solutions though.
Emotions, expressed clearly
There is a fun thing about emotions. People feel and express them differently, particularly across languages and cultures. This is difficult for an LLM to pick up on at the moment - unless you use the right ‘context’ then the right ‘tools’ then the right training data (and the right recipient), semantics, syntax, etc.
Therein lies the point. Translation, particularly between certain language pairs, remains difficult.
Let us have a look, step-by-step.
It comes down to:
The fidelity of the training data (for all training pairs of data - and the difficulty in reliable translations adds to this problem as more pairs are added).
Reliable translation (across language pairs). This is one or many ‘algorithm(s)’.
Check before delivery (this can be automated BUT you’d better speak many languages fluently to check (now and in the past) and then put a human check in place.
Delivery at designated time via email.
API keys stored safely, guardrails in place, etc.
Fun!
This can all be done - but must be carefully done.
Refining the Translation Engine
Translation between certain languages can be tricky. Context is the key element.
One can say “That was FUN!” with a different intonation to “that WAS fun”, for example (in English). So how do we make sure the correct translation occurs across language pairs, particularly in the case of ‘love’? at scale?
The steps start at: Collect, in this case, love phrases from different languages then translate into English. Then set-up a workflow that follows this pattern without breaching the ‘rules’ (part of the .md file).
The Phrase Library
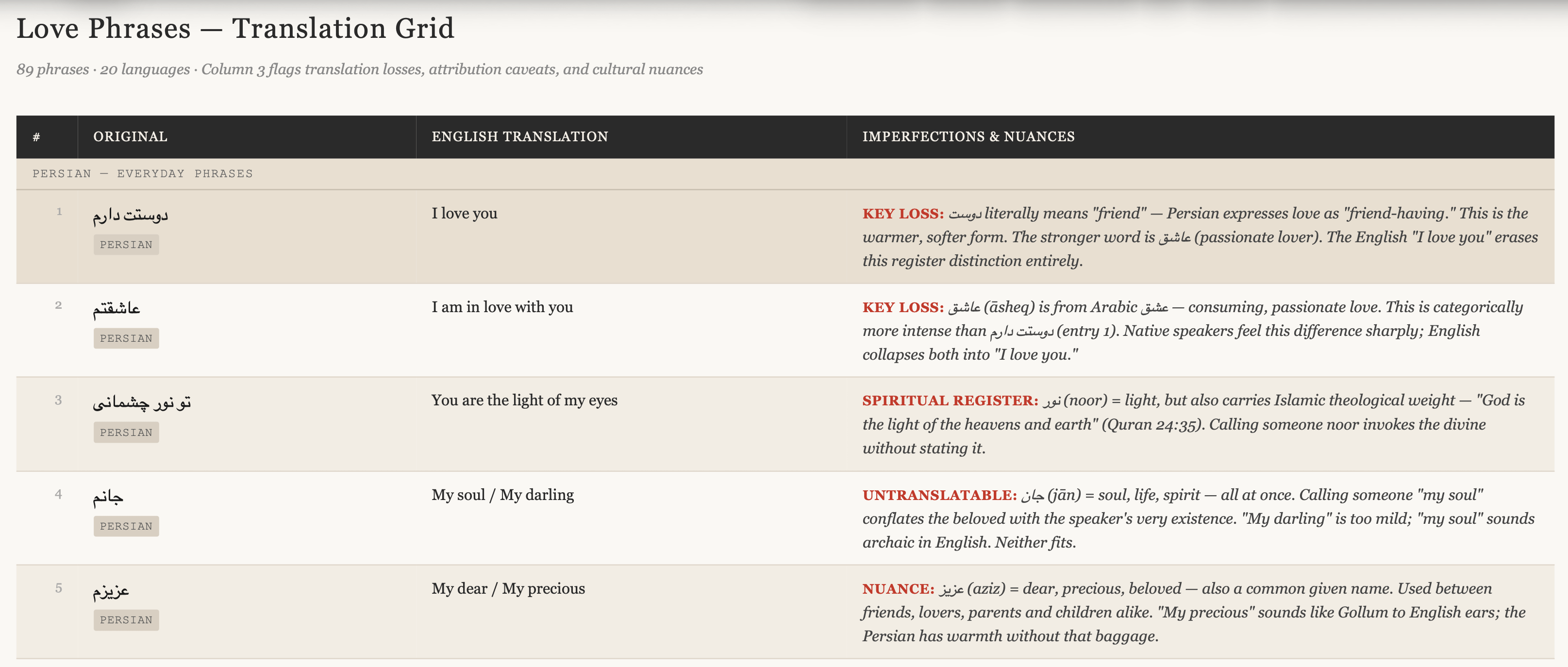
The heart of the project is a curated collection of 80+ love phrases drawn from across human history (i.e. those phrases that remain and have been digitized). This can be collected fairly easily.
Think Persian classics from Hafez and Rumi sitting alongside Neruda in Spanish, Pushkin in Russian, Sappho in Ancient Greek, Li Bai in Classical Chinese, Tagore in Bengali, Ghalib in Urdu, and the Song of Solomon in Hebrew.
Every entry has four parts: the original script (from non-English) then the English translation and a short note on its cultural context. For example:
دلم برات تنگ شده Delam barat tang shodeh “My heart has grown tight for you” — A poetic Persian (Farsi) way to say ‘I miss you.’
Each phrase is also paired with a matching image.
It is often a couple walking on a beach. Training data :)

How It Works
Every morning at 10am GMT, a Python script wakes up on my Mac and picks the phrase of the day. The phrase already has a send date. Everyone on the list (her) gets the same phrase at that designated time and it iterates through the 80+ phrases at midnight without any intervention.
The email arrives as a styled HTML message: warm cream background (romantic), serif font (romantic font - unlike ComicSans), with the original script displayed right-to-left where needed, the English translation below it and the image embedded inline.
The Two-Step Send
One element, which is important, is that the bot has a preview mode.
Before sending to the full list (her), it sends me: “PREVIEW — AWAITING YOUR APPROVAL.” I read the phrase, look at the test email and decide whether I want to send it that day. If I do then I just write ‘send to group’ and it goes out to her and me (that is correct grammar in English - more to that later).
NB: This is extremely important with LLMs. There needs to be certain checks in place depending on the process, or else, something bad can happen.
So What Can Go Wrong? (Even With Checks)
Languages are tricky things when translated from one to another. Add a third originating language and the interpreters become nervous. Now throw in an LLM where the training data is not known to the outsiders and something ends up taken out of context or simply outright wrong.
This is a very hard set of problems.
Let’s play a game with it.
Let’s start with the (x) language to English [there are many English variants] but to keep it simple let’s just stick with General English then match with the various languages.
This pair I cannot verify as my Farsi is non-existent.
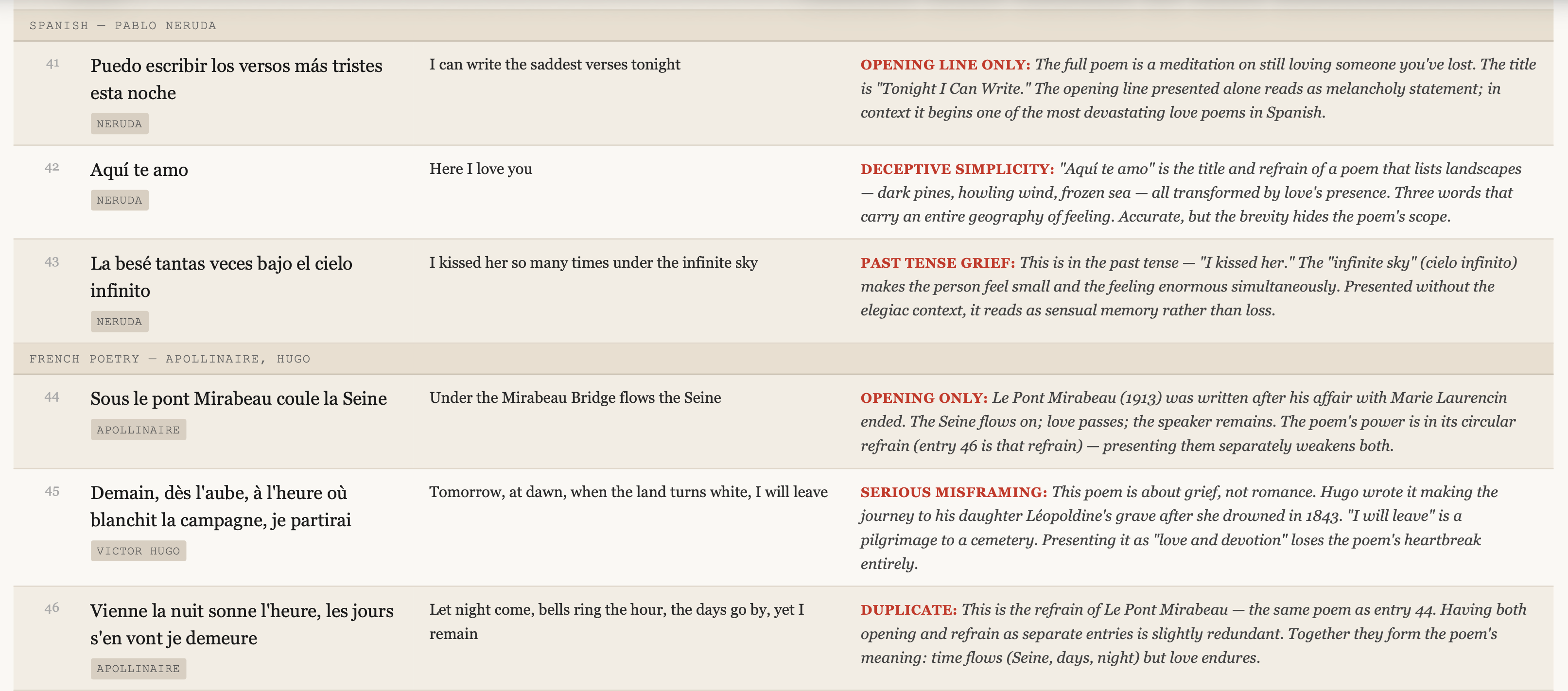
However, my French and Spanish are very good. The below translates the two commonly used match phrases between the two languages (including English).
By the way… the common use of ‘I love you’ in Spanish is: ‘Te quiero’.
It is one of the first things taught in basic Spanish (similar to, “I’m full” translates directly to “Je suis enceinte” in French. The former means “I’ve had too much to each, the latter “I am pregnant”.
For the reference, J’en ai assez’ is (one of the) correct forms in French to express the idea of having had enough food).
Let’s look now as Persian (Farsi) is checked against French - then translated to the English outcome…
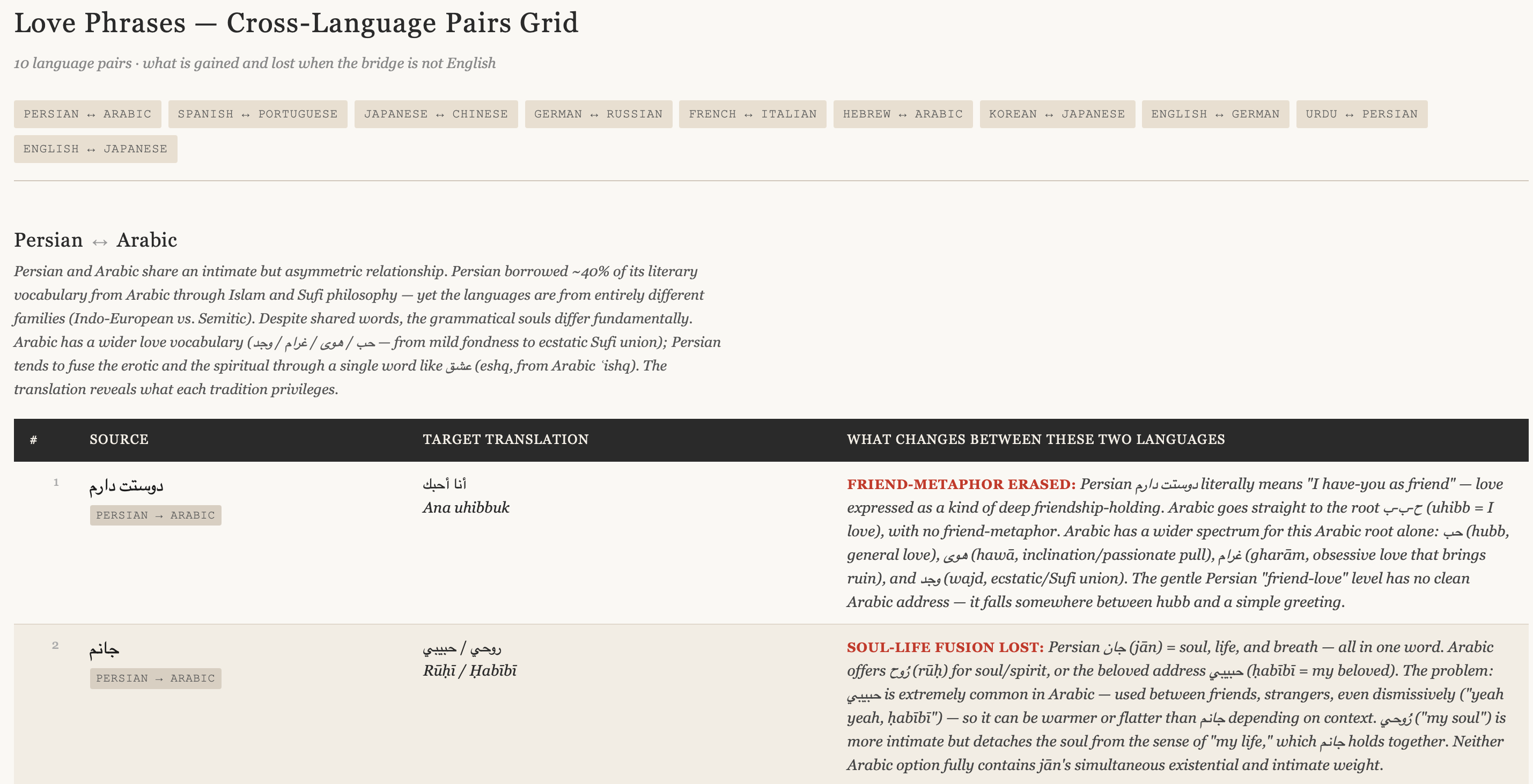
I could go on and on all day. There are many ways to refine this process - but one must check each against benchmarks! Then go back and re-write the .md, tools, hooks and all other pieces in an agentic AI workflow. This is just for the English word ‘love’.
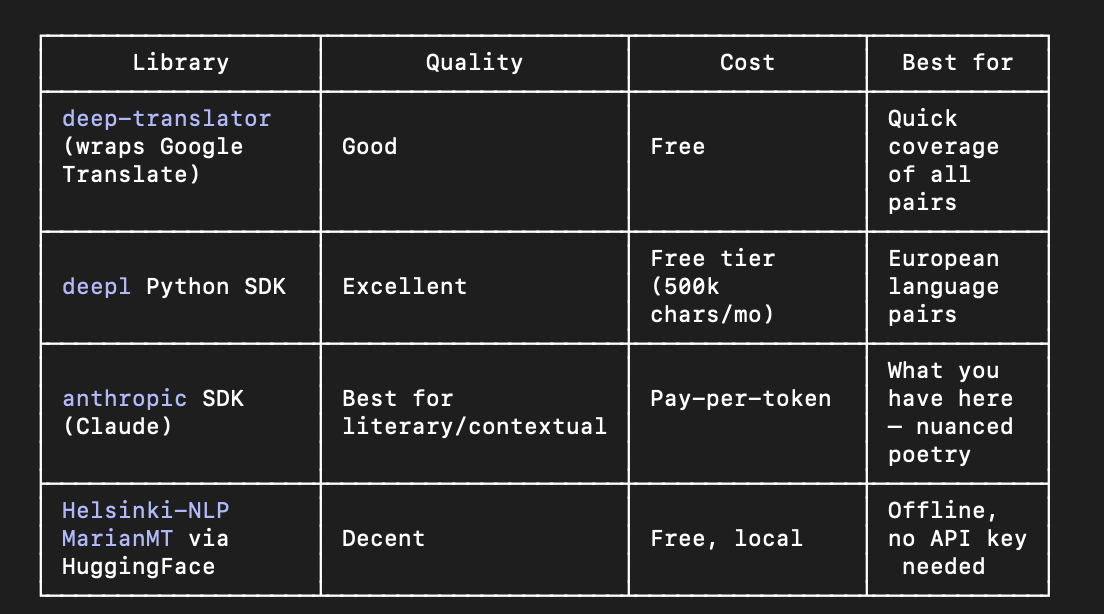
Finally - this is one I can verify between two languages (they are quite close). How many more of these are in the database? I could find out. The point is sufficiently made though.

Fin
So we’ve gone through an exercise in how to use/not use LLMs.
It is not very complicated to do this. There is a whole set of steps that need to be taken before doing anything like this, particularly with regulated companies and law firms, is done first.
Determine discrete desired outcome(s).
Set the rules under the .md file (this depends on desired outcome(s).
Put correct tools into a folder for repeated use.
Check that the training data are accurate (how accurate do they need to be?)
Translate - it the output correct? (given the context, and the language pair + does the output come originally from a third language via a second language… or more?
Use a reliable library of training data with the correct method to derive correct translations.
Fun (now did you think fun… or FuN, Ben)?
What did we find?:
A seemingly mundane is task not so mundane (especially if the original English verse is incorrect and the timing via cron incorrect)
Collecting training data: where does it come from and how does one know it is correct to begin with?
Translating in a repeatable pipeline: Regional/geographic English to x is different from a regional dialect of (for example) Magyar to a regional form of Georgian.
This is very important for regulated financial and insurance companies. Also law firms translating across languages.
This is the folder structure:
⏺ love_bot/
├── daily_email_bot.py # main bot: preview + send logic
├── persian_love_phrases.py # phrase library (25+ Persian phrases)
├── enrich_translations.py # translation enrichment script
├── run_bot.sh # shell runner
├── CLAUDE.md # project instructions
├── bot.log # runtime log
├── log.md # manual log
├── images/ # 52 JPGs matched to phrases (01_love.jpg …
52_hyacinth.jpg)
├── grid/ # HTML/MD phrase grids and heatmaps
├── blog/ # blog post drafts (translation errors article)
├── mistranslations/ # translation review notes
└── non_english_translations/ # translations grid in other languages
I’ll add the files if anyone cares to ask. Go to info@gadfly.now if you’d like.
Next week I’ll dive back into SEC Filings and their footnotes. Perhaps I’ll add a tool and open source it.